Why AI tools Have No Continuity

Every power user of AI tools has their own version of the ritual. Before you can get any actual work done, you spend five or ten minutes typing the same stuff you typed yesterday. Your name. Your tech stack. The decision you made last Tuesday about the database schema. The tone your boss hates. The three constraints that make this project different from every other project.
This is the fresh-session handoff. And it is costing you more than you think.
What the Handoff Actually Costs
Most people think of the handoff as a minor annoyance. A few minutes of typing before the real work starts. But measure it honestly: if you open a new AI session twice a day and spend five minutes on context re-entry each time, that is 50 minutes a week. Over a year, it adds up to more than 40 hours.
That is a full work week, spent typing things you already know into a box that forgot them overnight.
The time cost is real, but the cognitive cost is worse. Context re-entry is not passive. You have to reconstruct the mental model of your project, remember which decisions have been made and why, and figure out what level of detail the AI actually needs to be useful. You are doing project management inside your head before you can do any actual work.
And then you start typing.
How Power Users Cope (And Why It Breaks Down)
The people who feel this pain most acutely are the ones who have tried hardest to solve it. Browse any subreddit for AI power users, and you will find elaborate workarounds.
- Markdown files with project state summaries, pasted at the start of each session
- Custom instruction blocks in ChatGPT that grow longer every week
- Shared Google Docs serving as 'context vaults' that get copy-pasted into Claude
- CLAUDE.md files committed to repos so the coding agent at least knows the stack
- Elaborate note-taking systems where the user manually writes session summaries (Obsidian, Logseq, etc.)
These all work, up to a point. The problem is that they require you to do the memory work manually. You have to remember to update the markdown file. You have to decide what goes in the context vault and what does not. You have to maintain the system, prune it when it gets stale, and keep it consistent across tools.
In other words, you traded one problem for another. Instead of repeating yourself to the AI, you are now maintaining a second job: personal AI memory librarian.
The Real Problem: AI Sessions Have No Continuity by Default
This is not a user problem. It is an architectural one.
Every major AI tool, by default, treats each session as isolated. Claude does not know what you told ChatGPT. Cursor does not know the decisions you hashed out with your AI assistant last week. The context you build up in a long session disappears the moment you close the tab or hit 'New Chat.'
Some tools have added rudimentary memory features. ChatGPT now stores preferences and facts. Claude has started experimenting with memory across conversations. But these are narrow, tool-specific solutions. They remember surface preferences, not deep project context. They do not travel with you when you switch tools. And they give you no control over what gets remembered, updated, or retired.
The session boundary is the fundamental problem. Until something exists outside that boundary, persistent context remains a manual job.
What a Real Persistent Memory Layer Does
The handoff tax drops to zero when your context spans multiple sessions.
That is what Kumbukum is designed to do. It is a persistent memory layer that connects to your AI tools via the Model Context Protocol (MCP). When you start a new session in Claude, ChatGPT, or any compatible tool, the relevant context from Kumbukum is already available. The project state you were in. The decisions that have been made. The constraints that matter. Your preferences.
You do not paste anything. You do not maintain a markdown file. You do not write session summaries.
The AI you are talking to today knows what the AI you talked to last week knew. Because the memory layer persists, it travels across tools.
Here is a session in Codex. You quickly see how Kumbukum benefits the conversation.
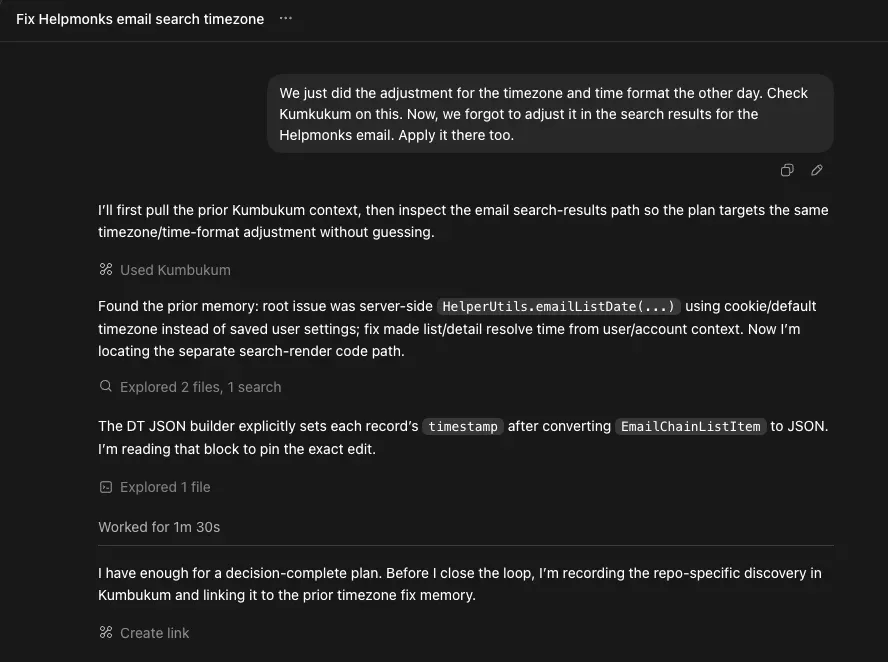
The Compounding Value of Context That Stays
There is a subtler benefit that goes beyond the time savings. When context persists, AI tools actually get more useful over time.
With the fresh-session handoff model, every session starts at zero. The AI is only as good as what you tell it right now. You can never build on previous conversations because those conversations are gone. The relationship stays shallow by design.
With persistent memory, the relationship deepens. The AI knows the arc of your project, not just the current snapshot. It can spot when you are about to repeat a mistake you made three weeks ago. It can apply decisions consistently across sessions without you having to remind it. It understands your preferences without you having to restate them.
That is the compounding value of context that stays. Not just time saved today, but better output every day, because the foundation keeps growing instead of resetting.
Start Eliminating the Handoff Tax
The fresh-session handoff is a workaround for a problem that should not exist. Persistent memory should be the default, not an elaborate system you build and maintain yourself.
If you are spending time every day re-explaining your work to AI tools, that time is not going to come back. But it can stop. The right memory layer eliminates the handoff entirely, so you can start every session exactly where you left off, across every tool you use.
One more thing that matters: Kumbukum is open source. You can inspect the code, self-host it, or contribute to the GitHub repository.
Try Kumbukum and see how much time you get back.