MemPalace Is Viral But Is It Real Persistent Memory?
MemPalace went viral. Thousands of GitHub stars in a week. Posts all over r/LocalLLaMA and r/ClaudeAI are calling it a breakthrough in AI memory. The demos looked impressive. The benchmark numbers were striking.
But dig into how it actually works and a question surfaces quickly: is this genuine persistent memory, or is it something more familiar dressed up in new branding?
The answer matters if you're a builder who needs AI memory that holds up in real work, not just benchmark conditions.
What MemPalace Actually Does
That's not retrieval-augmented generation in the classical sense. It's not a vector database fetching semantically similar chunks from an external store. It's context stuffing with better organization.
The distinction matters. Context stuffing, however smartly structured, has a hard ceiling: the context window. Grow the memory store large enough, and you hit the limit. Everything beyond that limit is unavailable until something gets evicted. Nothing actually persists outside the session. Close the window, and it's gone.
Why the Benchmarks Look So Good
MemPalace's benchmarks are real. On the tasks they measure, the system performs well. But look at what those benchmarks test: recall of structured facts within a session, with a preloaded memory graph that fits comfortably in context.
That's a favorable setup. Recall within a context window is a solved problem. LLMs are very good at it. The benchmark measures whether MemPalace's graph structure helps the model find relevant facts in a prompt faster than a flat blob of text does. It does. That's genuine, but it's a narrow win.
The harder problems, the ones that matter most to builders, are not what's being measured:
Can the memory survive a session reset? No. The graph lives in memory (RAM, not persistent storage). Close the session, and you start fresh.
Can it scale beyond context window limits? Not without manual pruning, which means deciding what to forget, which means context loss by another name.
Does it work across tools? No. MemPalace is a single-process library. It has no protocol for sharing state with Claude Code, Cursor, or ChatGPT.
Does it separate memory from the AI provider? No. You're still dependent on the LLM you're running it against. Switch models and you rebuild the graph.
The Open-Source Appeal (And the Honest Tradeoffs)
MemPalace's viral moment says something real about where builders are right now. There's a genuine hunger for open-source, inspectable, self-hostable memory. Developers are tired of black-box memory from AI providers that they can't audit, export, or version-control.
That instinct is right. Memory that you own, that you can read as plain text, that lives in your infrastructure instead of a vendor's cloud, is better memory in almost every practical sense. You can inspect it when something goes wrong. You can back it up. You can move it between tools. You can run it offline.
MemPalace gets credit for riding this wave with something open and hackable. The problem is that it addresses the visibility aspect of the memory problem without addressing the persistence aspect.
Seeing your memory in a readable graph format is good. But if that graph resets every session, you haven't solved the memory problem. You've solved the organization.
What Genuine Persistent Memory Looks Like
Real persistence means the memory exists in a durable store, outside any single session, independent of any single tool.
That has concrete implications for how the system is built:
Storage must be external. Not in-process, not in RAM, not tied to a single model instance. A database, a file system, a proper key-value store. Something that survives process termination.
The protocol must be tool-agnostic. If Claude Code can write to the memory store and Cursor can read from it, that's genuine shared memory. If each tool maintains its own isolated context, they don't share memory. They're just each building their own.
Retrieval must be decoupled from the context window. The memory store needs to be queryable independently of any particular LLM session. You ask for what's relevant, the store returns it, you inject what fits. The store itself doesn't have a context limit.
The format should be human-readable. This is where MemPalace's instinct is right, even if the execution doesn't deliver persistence. Memory you can open in a text editor, commit to version control, and inspect without running a model is memory you actually own.
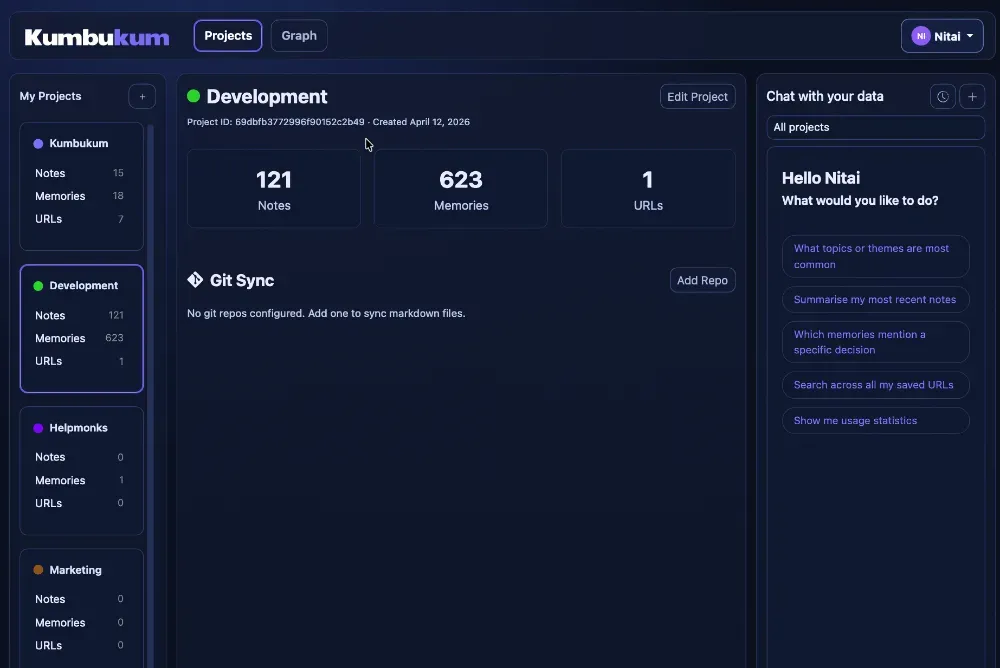
Kumbukum: Built for the Problems MemPalace Doesn't Solve
This is exactly the gap that Kumbukum was built to fill.
Kumbukum is a persistent memory layer that implements the Model Context Protocol (MCP), which means any MCP-compatible AI tool can read from and write to the same memory store. Claude Code, Cursor, Claude Desktop, and other tools all work from the same source of truth. A decision made in one tool is available in the next.
The memory lives in a proper database, not in-process. It survives session resets, tool switches, and model upgrades. There is no ceiling on the context window for the store itself. What gets injected into any particular session is a relevant subset, retrieved on demand.
It's also designed for builders who want control. The data model is transparent. You can inspect what's stored, tag memories for organized retrieval, and structure your knowledge base the way you want. No black box. No vendor-controlled memory that you can't audit.
Kumbukum's approach is also open and builder-friendly. Check the Kumbukum docs to see how the MCP integration works and how memory gets structured. The protocol is standard, the storage is yours, and the retrieval is inspectable.
Which Tool to Choose
MemPalace is a good experiment and an honest open-source contribution. If you want to explore structured in-session memory organization, it's worth looking at. The code is clean. The graph idea is interesting.
But if your requirement is memory that persists across sessions, works across tools, and scales beyond what fits in a context window, MemPalace is not the tool for that job. It was not built for that job. The benchmarks that show otherwise are measuring a narrower metric.
The builders who need real AI memory, the ones working on projects that span weeks, switching between Claude Code and Cursor and ChatGPT, building systems where context from last month still matters today, need something that actually stores state externally and retrieves it on demand.
That's the category Kumbukum sits in. Not in-session organization. Persistent memory across the full lifespan of a project.
The Bottom Line
MemPalace going viral is a signal, not an answer. It shows that developers want memory they can see, own, and control. They want open-source alternatives to proprietary AI memory. They want something that works the way their brain thinks memory should work.
Those are the right requirements. The gap is whether the implementation actually delivers persistence or just better-organized forgetting.
If you're evaluating AI memory tools, ask the question directly: Does the memory survive a session reset? Does it work across multiple tools? Can you inspect and export it without running a model?
If all three answers are yes, you have persistent memory. If any answer is no, you have context organization with better UX.
Start with the right question, and the right tool becomes obvious. Try Kumbukum Cloud for free and connect it to your existing AI setup. Your memory will be there when you come back.
Kumbukum is open source. You can inspect the code, self-host it, or contribute to the GitHub repository.